In my last post I discussed the importance of using a regularized classifier to avoid overfitting the data. I used contour plots to show the distortions in the decision boundaries of a logistic regression classifier on artificial data. Recently I have been going through Nigel Lewis’ “Build Your Own Neural Network Today!” and decided to try out a neural network on the same dataset. The author is very enthusiastic about predictive modeling and his books are interesting. If you want to get on his newsletter shoot me an email and I will forward to you. You can buy his book for less than a pack of Canadian smokes so I would recommend you pick up a copy.
Today I will use R’s nnet and caret package on a synthetic dataset that is plotted below.
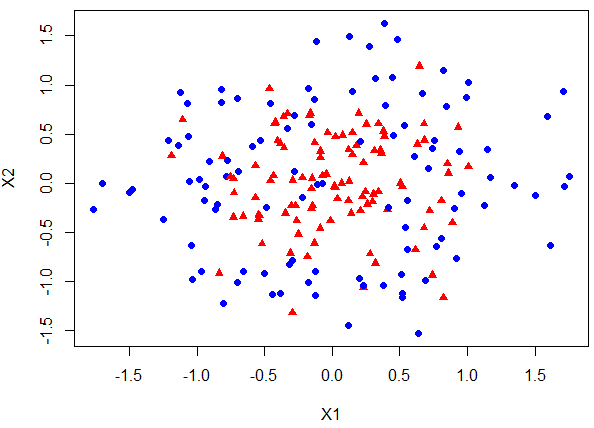
The red triangles are classified as 1 and blue circles are encoded as 0. Using R’s nnet we can build neural networks with a single hidden layer and varying number of hidden neurons to see how models with different degrees of complexity fit the data.
Below is the screenshot of the code used to fit a neural network with a single hidden layer that has one node. From the contour plot you can see that the classifier does a terrible job of making distinctions between the two classes.


We can repeat the exercise by increasing the size argument of the nnet function which controls the number of nodes in the hidden layer. Below are the contour plots:

It is clear that for a single hidden layer, as we vary the number of nodes, the decision boundaries change dramatically. In models that have more than 3 hidden nodes we can see that decision boundaries are chasing the idiosyncrasy of the data. In many regions the decision boundaries for varying threshold levels are very close together. The implication is that the estimated probability from our classifier underestimates the uncertainty with which we assign labels to the classes.
Above analysis only varied the number of nodes in a single hidden layer. Typically, modellers have a choice of increasing the number of hidden layers, and also to engineer features such as x^2 and include interaction terms between features. The dangers of using deep neural networks (many hidden layers) and excessive amount of nodes should be obvious from above analysis.
If you have read my last post I suspect you can already tell that all is not lost, we have a remedy at our disposal. Regularized neural networks can assist us. Regularized neural networks are just an extension of other penalized models that I have discussed previously such as ridge regression and lasso model. In a future post I will derive back propogation algorithm for training a neural network with a penalty term for the weights. Here I want to show you how we can implement it in R using caret package.
Below is screenshot of the code:
The basic idea is to set up a grid of tuning parameters such as weight size penalty (in nnet function decay argument is the weight penalty parameter) and size of the network. Nnet package handles neural networks with only a single hidden layer. Neuralnet package can build neural networks with more hidden layers but a major drawback is that the network is not regularized.
In this example I kept 7 hidden layer nodes and will only search for optimal weight decay. In reality, we should search across multiple hidden layer node inputs and penalization weights. I forced the model to use 7 nodes so we can contrast regularized network against the decision boundary plots we got earlier.
Plotting the accuracy (using repeated cross validation) of each model for a given weight decay we can see that a model with .01 wins out.
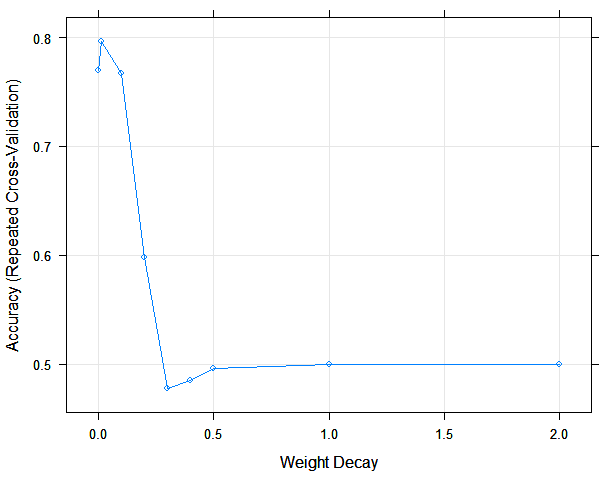
The contour plot of the best model is shown below. Arguably, the decision boundaries make a lot more sense for this model. They are not as nice as the ones we got using penalized logistic classifier in my previous post but my aim is not build the best classifier on our fictitious data, it is to highlight the importance of introducing regularization to our models to simplify them so they generalize well instead of building flexible complex models that overfit the data.

In my next post I will go into some depth of how backprop training algorithm for a neural network can be modified to include a penalty for the size of the network weights.
Useful Resources:
- N Lewis’ Build Your Own Neural Network Today! http://www.amazon.com/Build-Your-Neural-Network-Today/dp/1519101236
- N Lewis’ Deep Learning Made Easy with R http://www.amazon.com/Deep-Learning-Made-Easy-Introduction/dp/1519514212
- Amazing book by Kuhn and Johnson Applied Predictive Modeling. If you use R for machine learning you will keep coming back to this book. http://appliedpredictivemodeling.com/
- My post on regularized logistic classifier https://quantmacro.wordpress.com/2016/03/22/shaving-a-classifier-with-occams-razor/
- Background on neural networks and how to train them https://quantmacro.wordpress.com/2015/08/13/artificial-neural-network-with-backpropagation-training-in-vba/

Hi! Cool post, thanks for that! One (maybe stupid) Question: how did you simulate your data exactly // where does the function make_circle() come from?
Thanks in advance, Marius
LikeLike