Quick Refresher:
I have previously discussed penalized regression models in the context of ridge regression and the LASSO model. These two models are special cases of the elastic net model. Recall that in Ridge regression we included an L2 penalty term in our sum of squared errors loss function which we attempt to minimize to estimate our theta parameters:
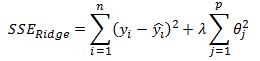
The lambda term is a hyper parameter and is estimated using cross validation.
A higher value of lambda shrinks the model’s coefficients towards zero. The particular choice of using an L2 penalty term means that our estimated theta coefficients approach zero but do not equal zero exactly.
In my post on Ridge regression I presented a plot of coefficient paths as a function of lambda.
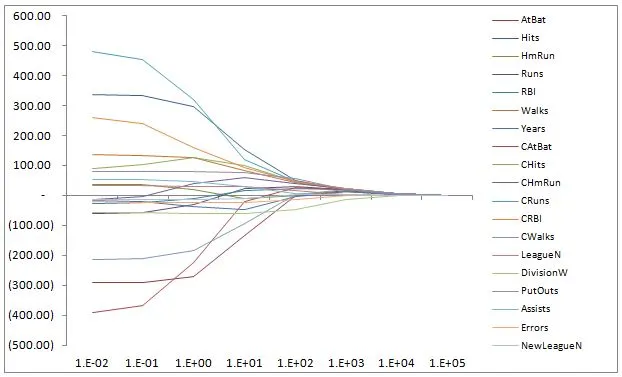
Penalized linear regression models try to balance the bias variance trade-off by imposing increased bias in exchange for a (hopefully) larger decrease in the variance of the model.
The LASSO model uses an L1 penalty term in the loss function we are trying to minimize:
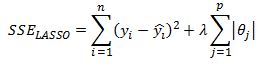
The lambda parameter serves the same purpose as in Ridge regression but with an added property that some of the theta parameters will be set exactly to zero.
Elastic Net:
The elastic net model combines the L1 and L2 penalty terms:

Here we have a parameter alpha that blends the two penalty terms together. When alpha equals 0 we get Ridge regression. If alpha is set to 1 then we have the LASSO model. The lambda parameter is the shrinkage coefficient.
R implementation:
To estimate the model in R we can use the glmnet package that has elastic net model implementation. In glmnet we can perform cross validation to find the lambda parameter that returns the smallest possible root mean squared error statistic for a selected alpha parameter. This approach is useful when we decide apriori on what alpha we want to use. If we have resolved to use Ridge regression we can perform cross validation to find optimal lambda while keeping alpha set to 0. Alternatively, if we wish to find the optimal lambda for the LASSO model we would set the alpha parameter equal to 1.
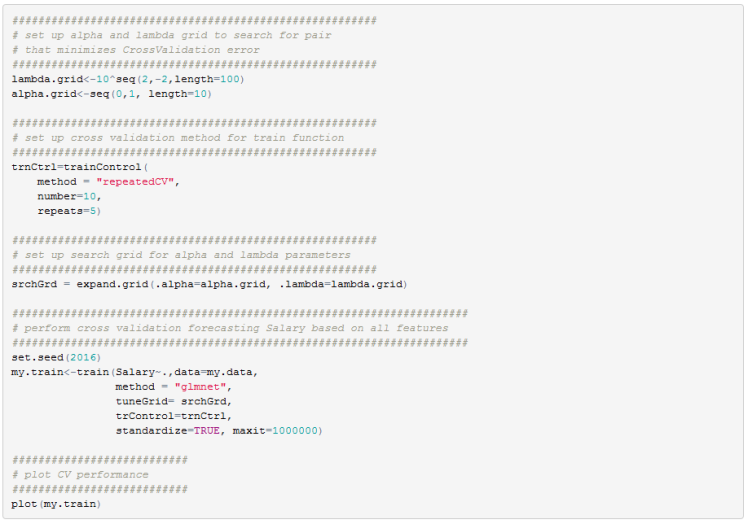
In our case we want to find the optimal lambda and alpha jointly. For that we will need to use the caret package. Using the train function in the caret package we can set up a grid of alpha and lambda values and perform cross validation to find the optimal parameter values.
Below is an example using Hitters dataset from ISLR package.

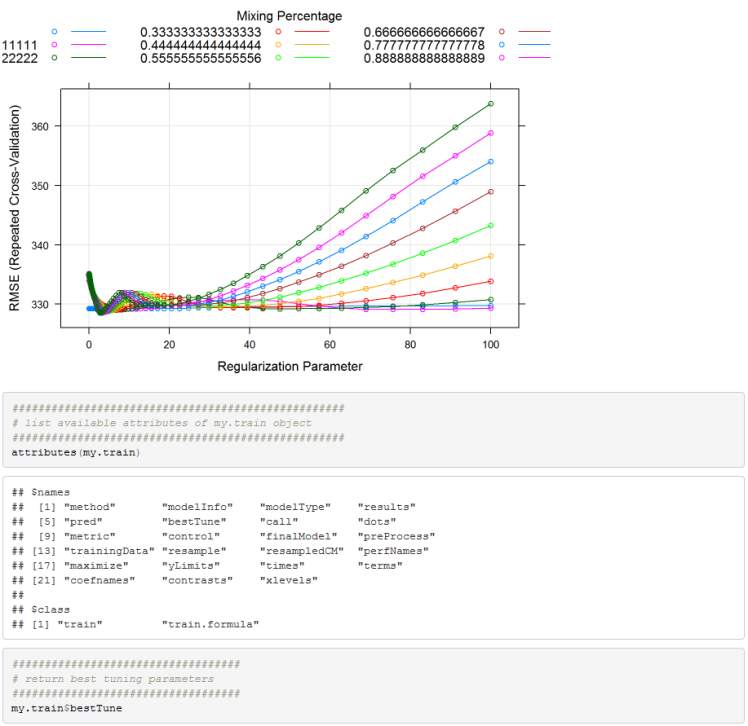
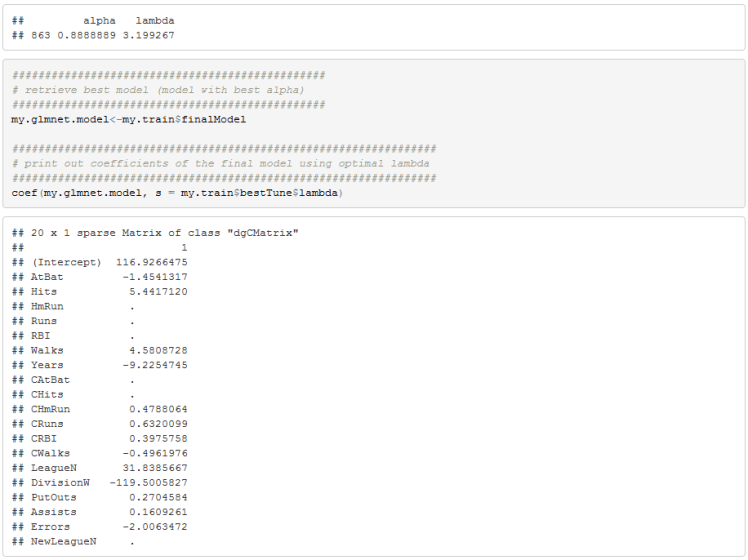
Practical Model:
If I haven’t lost you with the baseball dataset I want to show you a more practical model. Many brokers produce toy regression models as a sanity check of valuations in FX. Below is one example produced by a shop that is particularly fond of these models.
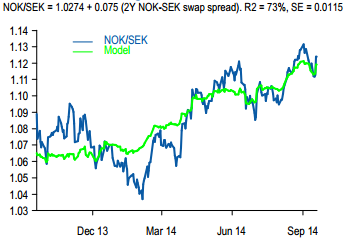
We can use elastic net to estimate similar models that will generalize better (we hope). In addition to using elastic net, I like to use interaction variables. Let me digress for a minute to explain interaction variables in the context of an FX fair value model. Usually an FX pair is regressed on rate spreads, perhaps relative equity index valuation, and let’s say the VIX index to capture risk aversion. A model would be estimated as:
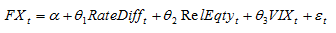
We can include interaction terms as follows:
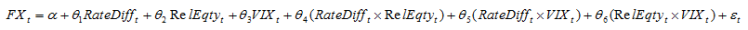
I realize that this seems odd but we can group the variables together and then factor to get:
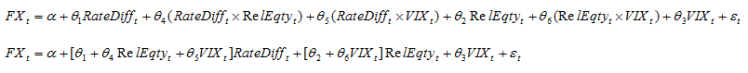
Notice that what we end up with are theta coefficients that are dependent on the features. For example, the impact of rates spread is dependent on the level of relative equity valuation and the VIX. By introducing interaction terms we can pick up interesting dynamics that usual linear regression models cannot. If such theta-feature dependencies exist, and are not swallowed by noise, we should be able to pick them us using our elastic net model.
Elastic Net FX Model:
With a little bit of effort we can shoehorn elastic net models into excel and have live models for select FX pairs. Below is an example of a model for EURAUD. I cannot stress enough the importance of including out of sample test data to check how well our model generalizes. If the model does a decent job of fitting the test (out of sample) data then we can place more confidence in our model.
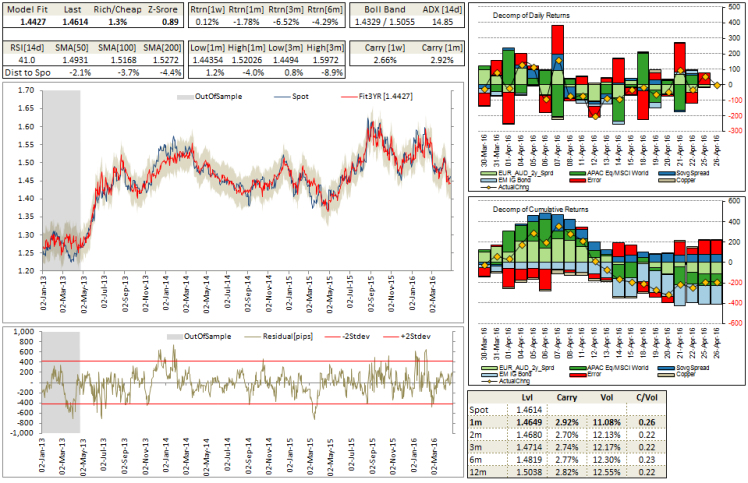
There are instances where our model does well on training data but does not generalize well. For example, AUDJPY model fits well in-sample but does a poor job out of sample.

A Warning:
I want to end on a cautionary note. These models are useless for systematic trading. They backtest poorly. I believe they are extremely useful for scenario analysis or as input into discretionary trade selection but should not be used to trade FX just because the market deviates from the model. This should be obvious to everyone. If we make a generous assumption and assume our model captures a real relationship between the target variable and the features, we still cannot trade that signal using the FX pair. If we observe a deviation of the market price from our model price there is nothing that forces the FX market to clear that difference. It is just as plausible for the rate spread to realign the model price to the market value of the FX pair.
Some Useful Resources:
-I keep telling you to pick up Applied Predictive Modeling by Max Kuhn and Kjell Johnson. Its well worth the money. http://appliedpredictivemodeling.com/
-An introduction to Statistical Learning is another great book. Some of the authors built the glmnet package. http://www-bcf.usc.edu/~gareth/ISL/
-Glmnet vignette https://web.stanford.edu/~hastie/glmnet/glmnet_alpha.html#lin
– My post on Ridge regression https://quantmacro.wordpress.com/2015/12/11/ridge-regression-in-excelvba/
– My post on LASSO model https://quantmacro.wordpress.com/2016/01/03/lasso-regression-in-vba/

I have a n00b question for you…..I’ve used nn in R to make networks, and used those to predict outputs based on new data. With the above (the Hitter example), you end up with coefficients for all of the variables; how can that then be applied as a predictor with a new dataset?
LikeLike
I realize this may be a bit too general, but for building FX fair-value models what is your preferred regression method? It seems LASSO and Ridge are very similar.
Do you typically use raw prices or returns when creating such models? And how should one account for differences in variation in each of the variables that go into such models. For instance, the equity factor is far more volatile than rate differentials, which would typically lead to a larger coefficient.
And finally, how did you generate the decomposition of daily and cumulative returns? I’ve never seen that done before and it’s certainly very interesting.
Thanks so much for generously sharing your knowledge. Huge fan of your blog, definitely consider it to be the best out there. I’ve had a blast working through your tutorials.
LikeLike
This is an excellent post and appears to hold the answer to the question that I’ve been searching to answer for days. I’ve been trying to work out how to get the coefficients that correspond to the best tuning of both lambda AND alpha. You say that `my.glmnet.model <- my.train$finalModel` contains the model with the best alpha. Is there a resource you can point me to that validates this? Because unfortunately I can't find it in the train() documentation. I've been wrecking my brain trying to work out how to get the coefficients for the best alpha! Thanks again! Steve
LikeLike
repeats = 5 gives a warning stating that it is not a valid parameter for the method in trainControl…Is it fine if we do not put this parameter
LikeLike
Sorry, ignore the comment..case sensitive
LikeLike