For a while now I had the intention of trying to use text mining techniques on central bank news releases. Until today I have been hesitant because I was not sure of how to scrape the text from webpages. Today I bit the bullet and went through R’s documentation and scoured coding forums. Below is a short note for anyone who wants to get the text content of a webpage into R for statistical analysis.
I will use Fed’s Apr 2016 press release webpage as an example. Our goal is to import the content of the page into R and then to parse the data so that we are left with just the text organized in some efficient data structure.
We first need to load the RCurl package and use getURL function to request and retrieve the content from a web server. The returned object is a vector of length one that contains the retrieved information.

Our aim is to extract the main text of the page and discard all other data that was returned to our request. To achieve this we first create a tree structure from the Apr2016.request object using htmlTreeParse function from the XML package.
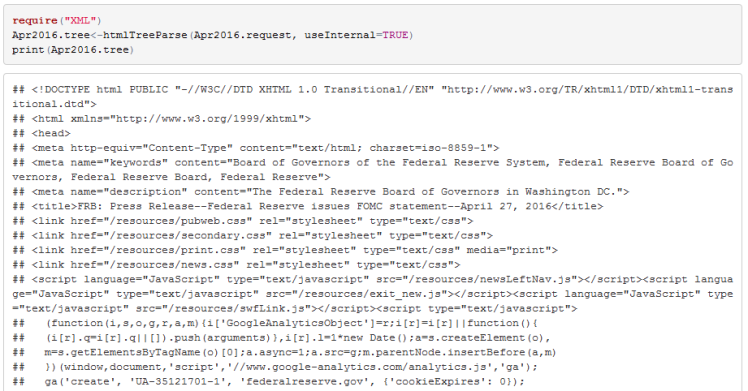
If you inspect the Apr2016.tree content you will notice that the main text of the webpage is contained in the paragraph <p> tag.

We can use xpathApply function to extract the content of each paragraph. To return a vector instead of a list we will unlist the output.
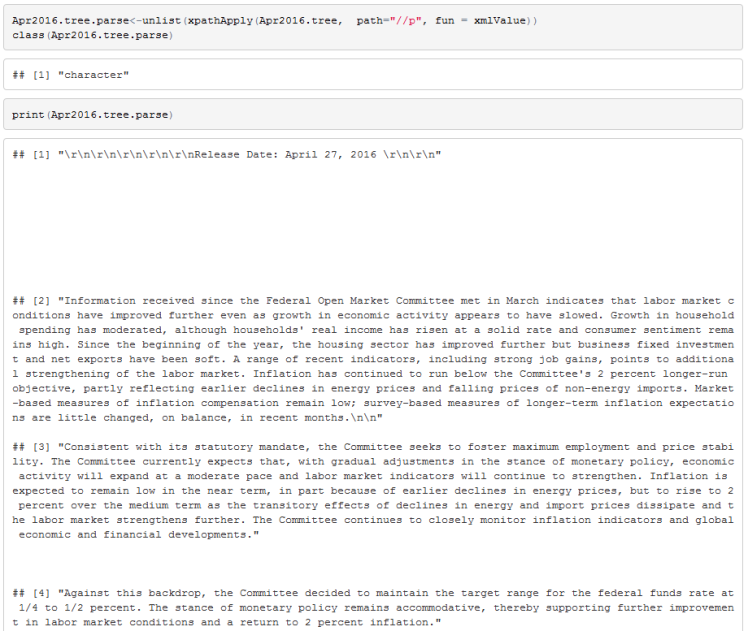
We now have the content of all the paragraphs of the Fed statement in a single R object. To perform text mining we can use R’s tm package.
We first need to create a text corpus which is just a structured set of documents. For that purpose we can use tm’s Corpus function. To create a corpus object from a vector of text we should use VectorSource function. VectorSource function interprets each element of a text vector as an individual document. So far, our Apr2016.tree.parse vector has a paragraph as its element so we need to combine each paragraph into a vector of length 1. I use a loop and omit the first paragraph (the date of the statement) and the last paragraph (link to Fed’s policy implementation notes).
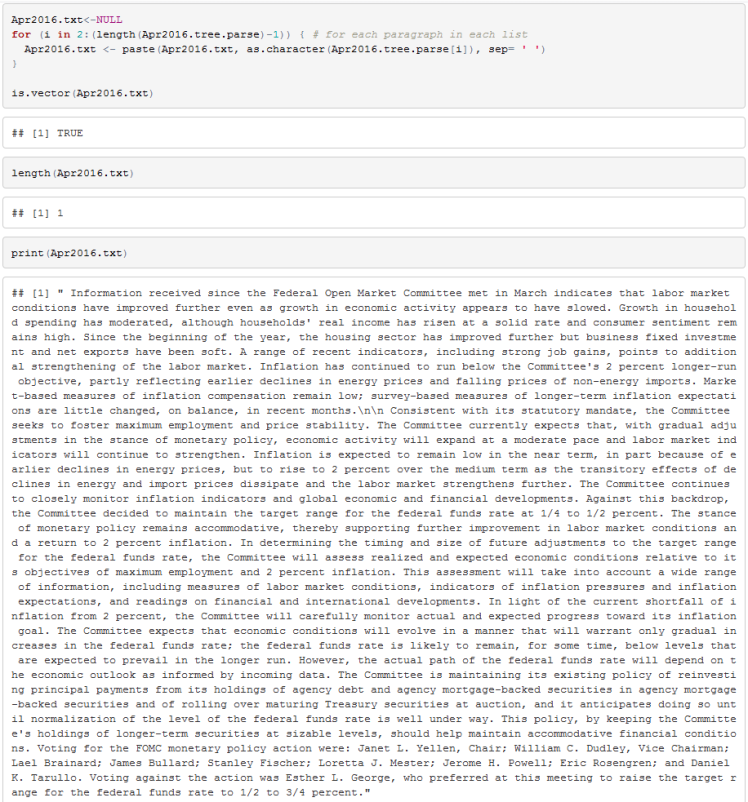
Finally we should remove \r (carriage return) and \n (new line) strings from the text and then create a corpus.

Now we can use tm’s text mining functions to change all words to lower cases, remove punctuation, strip out white space, and to remove stop words. Stop words are commonly used words that are often removed from a corpus before any analysis is performed. Typical stop words are ‘me’, ‘what’, ’were’, ‘who’, ‘is’, etc.
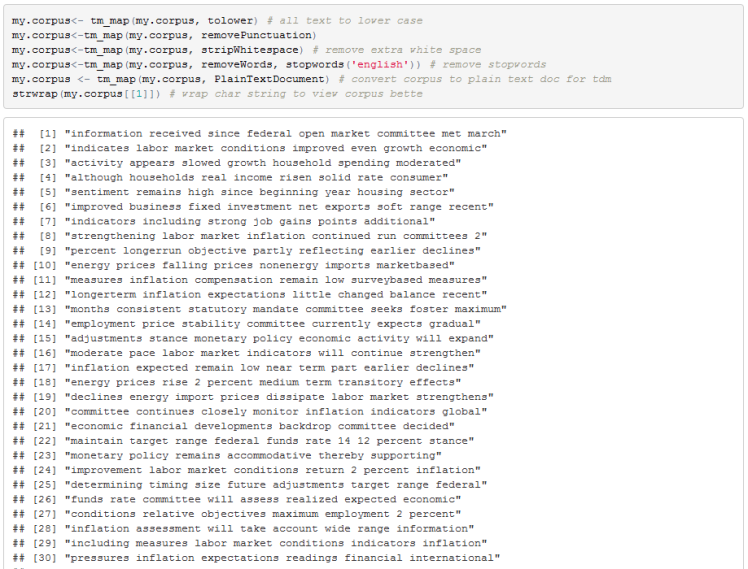
Once we have a corpus that is prepared for analysis we can change the data structure to a term document matrix. A term document matrix has a row for each unique word and the value in each row is the number of times that particular word appears in a document. Each column belongs to a particular document in a corpus. In our case we have a single document so we have one column.

And that is all there is to it. We now have the Fed statement document ready for text mining. To conclude the post I will simply create a wordcloud of the statement just because I feel like today’s entry lacks colour. The example is taken from Nigel Lewis’ book on data visualization.

Useful Resource:
- Tutorial on tm package https://cran.r-project.org/web/packages/tm/vignettes/tm.pdf
- I use http://stackoverflow.com for all my coding needs. Great community. If you have a question about R, most likely its been answered on this forum.
- LSE “Text mining for central banks” is an interesting piece on text mining http://eprints.lse.ac.uk/62548/1/Schonhardt-Bailey_text%20mining%20handbook.pdf
- Excellent book on data visualization where I took the wordcloud example http://www.amazon.ca/Visualizing-Complex-Data-Using-R-ebook/dp/B00I7I0VPQ?ie=UTF8&*Version*=1&*entries*=0

works like a charm! thanks for sharing. Now I guess I have to edit the stop words to include some common “fed” words too. Also I think a nice exercise will be to compare tdm of paste statements
LikeLike
Reblogged this on MyStats and commented:
Thanks!
LikeLike